
Fuzix-Compiler-Kitの6800用コンパイラ(2)(ベーシックマスター開発 その34) | ず@沖縄の続き。
同じ問題を解くプログラムを走らせて EFuzix C Compiler ProjectのCコンパイラと、拙作のGAME言語コンパイラの速度を比較したところで前回は終わりました。今回はその続きです。
同じアルゴリズムにしてみた
前回の記事を投稿した後に考えたのですが、同じアルゴリズムで比較した方が良いのではないかと気付きました。
そこでGAME言語用のプログラム(非再帰版)をCに書き換えて実行してみましたが、再帰版よりも遅くなってしまいました。
M1 Macbook Airで実行させても、非再帰版が遅いので、アルゴリズムとしては再帰版の方が良さそうです。
| プログラム | 実行環境 | 実行時間 | 実行サイクル数 |
|---|---|---|---|
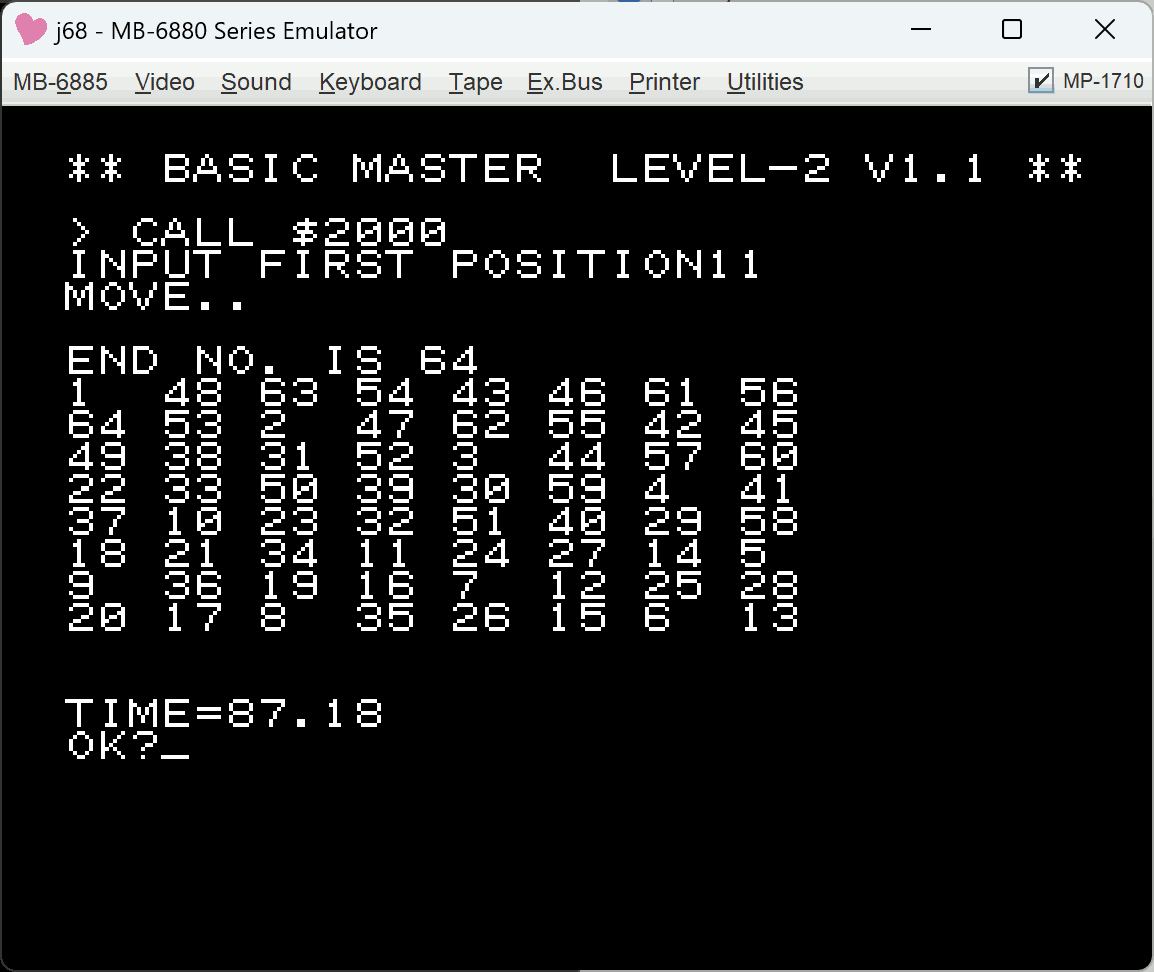
| GAME言語非再帰版 | 拙作のコンパイラ | 87.18秒 | – |
| 非再帰版C言語移植 | Fizux-CC | 250秒※1 | 188,308,353 |
| 非再帰版C言語移植++ | Fizux-CC | 243秒※1 | 183,695,721 |
| 再帰版C言語 | Fizux-CC | 209秒※1 | 157,440,530 |
| 非再帰C言語移植 | M1 Macbook Air | 8ms | – |
| 再帰植C言語 | M1 Macbook Air | 5ms | – |
- ※1 実機ではタイマー割り込みが1/60秒ごとに入るのと、画面表示に時間がかかるので、エミュレータの実行サイクル数から計算した値よりも遅くなります。
考察の前に
それぞれ、どれぐらい速い(遅い)のかを見てみましょう。
非再帰版をGAMEとFuzix CCで比較すると、2.86倍の差があります。
Macbook Airでは早すぎてわからないので1000個目の解までの時間を測ったところ、再帰版は0.132s、非再帰版は0.131sでした。あんまり変わらないですね。
アルゴリズムとしてはほぼ同等でしょうか?(要考察)。
非再帰版で比べてみる
非再帰版同士では、6800用のコンパイラ同士で2.86倍の差があります (87.18秒 対 250秒)。
この差はどこから来ているのでしょうか?
除算が遅い?
最初の解が表示されるまで21,970の局面を検査しています。この間に盤面外のチェックのために剰余計算が47,618回呼ばれます。
剰余はFizix CCでは除算ルーチンを呼んでいて、1回あたり700サイクルぐらいかかります。
拙作のコンパイラは10の剰余は専用ルーチンを使っていて、168サイクルで剰余演算を行います。速度差のうち30-40秒ぐらいは、剰余演算ルーチンの性能差です。
剰余ルーチンの性能差を除いても、GAME版とFizix-CC版は2倍ぐらいの差があります。
遅い配列計算をいかにサボるか
6800は、16bitの加算命令がない上に演算はAccA,Bでしか行えません。
J[K]のアドレスを求めるだけでも以下のようなプログラムになります。コストがかかりまくりなので、これをサボる必要があります(30cycleかかります)。
ldab _K+1
ldaa _K+0
lslb
rola
addb #<_J+0
adca #>_J+0
staa @tmp
stab @tmp+1
ldx @tmp
プログラム中で J[K]=J[K]+1 のような加算を ++J[K] にすると、2.5%ぐらい早くなります。上の表の “非再帰版C言語移植++” は、その変更を入れたものです。
拙作のGAMEコンパイラは、最適化して上記のような単純な加算の場合はアドレス計算を一回で済ませるようにしています。
遅い配列計算をいかにサボるか(2)
プログラムでは、添字が同じ配列や、似たような配列を使うことがあります。後者は J[K]=J[K+1] などです。
拙作のGAMEコンパイラは、同じ添字や近い添字(+1〜+126)のアドレス計算は1回で済ませるようにしています。違う行にあっても、なるべく1回で済ませます。
以下のプログラムだと、J[K+100]、J[K] のアドレス計算は1回だけ行っていて、あとは一時変数を使い回しています。
(K=K-1 で一時変数を捨てていますが、ここはもう少し頑張れるかも?)
U=J[K+100]; J[U]=0;
J[K+100]=0;
J[K]=1; K=K-1;
その代わり、ローカル変数や二次元配列もない言語なのに、コンパイラのソースコードは、アドレス計算だけで500行ぐらい使っています。
スタック操作が重い
Fizix-CC が出力するオブジェクトは、スタックマシンになっていて、大半の演算はスタックトップとAccA,Bの間で行われます。これが遅いのです。
6809であれば、スタックポインタ相対アドレッシング( n,u ) が使えるので なんでもないのですが、6800では tsx してインデックス相対にする必要があります。
IXレジスタはアドレス操作にも使いますので、毎回毎回tsxが発生します。しかも積んだスタックを戻す(ins)のも遅いです。pshb/psha … tsx … ins/insで20サイクルもかかります。
Fizix-CCでも右辺が定数や絶対アドレスのときは最適化しているのですが、それ以外の場合(特にローカル変数・配列)は莫大なコストが発生します。
拙作のGAMEコンパイラは、スタックにはなるべく値を積まないようにしています。最初のバージョンはスタックマシンで、その時は猛烈に遅かったです。
ヘルパー関数呼び出しが遅い
Fizix-CC では、関数呼び出し時に積んだ引数を、呼ばれた側の関数が破棄するようにしています。これが遅いです。6809ならLEAX命令一発なのですが、6800では莫大なコストがかかります。
乗除算なら、そもそもの計算が重たいからまだいいのですが、現在のFizix-CCでは比較演算・論理演算なども関数呼び出しになっています。つらいです。
関数は定義する回数よりも呼び出しする回数が多いはずなので、呼び出し側でスタックを破棄すると全体のプログラムサイズが大きくなります。
なので、呼ばれる側で破棄するのはプログラムサイズを抑えるためには必要なのですが、速度が犠牲になっています。
拙作のGAMEコンパイラは、比較演算も関数ではなくインラインにしていますが、そのために比較演算をコンパイルするプログラムは長大(コメント入れて800行)になっています。
使用目的の差
Fuzix-CC は Fuzix OSの記述用に開発されています。複数のプログラムが動作しますし、割り込みもあるので、リエントラントなオブジェクトを作る必要があります。
そのためには、なるべくゼロページを使わずに、スタックだけで操作を完結する必要があります。
6809ならゼロページは複数持てますし、リエントラントにするのも簡単です。
メモリ上で複数のタスクが動作するので、MMUがない機種を考えると(ある程度スピードを犠牲にしても)プログラムサイズを小さくする必要があります。
拙作のGAMEコンパイラは、上記のことを考慮しないで良いのでやりたい放題です。速いのも当たり前でしょう。
Fuzix OSから離れて、昔の8bit機環境で単独に動作するように Fuzix-CC を書き換えて、どれぐらい速くなるか見てみたいものです。
コメント