
前回はさまざまな乗算処理を見てみた。今回は除算。乗算ではシフト方向によって 大きく2つの方法があるが、除算も同様。
また、16bit*16bitの乗算で結果の下16bitだけを使う場合は符号あり・符号なしのどちらでも同じルーチンが使えるが、除算の場合は事前に正の数に直しておく必要がある。
(GAMEやNTBでは、言語仕様としても正の数として処理する必要がある)。
また、除数を引いてみて引けなければ即時に戻す方法(引き戻し法・回復法)と、次の桁の処理時に辻褄を合わせる方法(引き放し法・非回復法)がある。
GAME言語の除算
GAMEでは、人間が筆算するのと同じ方法で除算を行なっている。実際の手法については、ASCII.jp:CPU黒歴史 大損失と貴重な教訓を生んだPentiumのバグ (2/3)の例がわかりやすい。
プログラムサイズを小さくするために、原プログラムではサブルーチンを多用しているが、わかりやすくするために下記に引用したプログラムはサブルーチンを展開してある。
まず、除数を最左bitが 1になるまで左シフトする。Carry flagが立つまで左シフトして行きすぎた1bit分を右シフトしている。
(Cではなく、N flagを見るようにしたら2回分儲かりそうだが、除数が32768の場合を想定しているのだろう)
以下は筆算同様に引き算を行い、引けなかった場合は引き戻し法で元に戻す処理を行なっている。なので、引けた場合と引けなかった場合で必要時間が異なっている。
最悪の時間がかかるのは 0を1で割る場合で、最初に16+1回、次に16回のシフトが発生する。引き戻しも16回行われる。
大きな数、例えば32767なら最初のシフトが 1+1回、次も1回で3回のシフトで済む。
大抵の場合は除数は小さな数字だろうから、平均的な計算時間は不利になる。
また、除数を0ページに置いているため、シフト操作で14cycle必要になるのも痛い。
1バイトスキップに $9C を使っているのは、Cフラグに影響を与えないようにするため。細かい工夫である。BRAだと1バイト余計に必要になる。
DIVPOS CLR W66 ; 6 3
DP1 INC W66 ; 6 3
ASL 1,X ; 7 2
ROL 0,X ; 7 2
BCC DP1 ; 4 2 ↑ 24cycle/loop
ROR 0,X ; 7 2
ROR 1,X ; 7 2
CLR W68 ; 6 3
CLR W68+1 ; 6 3
DP2 SUBB 1,X ; 5 2
SBCA 0,X ; 5 2
BCC DP3 ; 4 2
ADDB 1,X ; 5 2
ADCA 0,X ; 5 2
CLC ; 2 1
FCB $9C ; 4 2
DP3 SEC ; 2 1
ROL W68+1 ; 6 3
ROL W68 ; 6 3
DEC W66 ; 6 3
BEQ TDE ; 4 2
LSR 0,X ; 7 2
ROR 1,X ; 7 2
BRA DP2 ; 4 2 ; ↑70 or 56cycle/loop
TDE RTS ; 5 1
GAMEの該当部分のソースはASCII誌連載二回目(1978年7月号)に掲載されている。
GAME68コンパイラの演算ルーチンも上記と同じ。
NAKAMOZU Tiny BASICの除算
NAKAMOZU Tiny BASICでは (IX+2,IX+3)/(IX,IX+1) → (IX+2,IX+3) という処理を行なっている。
プログラムサイズを小さくするために、原プログラムではサブルーチンを使っているが、下記に引用したルーチンはそれを展開してある。
こちらは商と除数を連結して4バイトずつ左シフトしている。シフト回数は除数の大小によらず16回である。
ループ部分は MDV1〜BNE までで、1ループあたり 70cycle(分岐不成立時)、58cycle(分岐成立時)である。
MDIV4は、被除数の最上位ビットを見て引き戻しを行いつつ、Cフラグを設定している。設定したフラグはMDV2のDECでは壊れないのがミソであるが、難解。
乗算のときと同様に、インデックスアドレッシングをダイレクトモードに変えれば 所用時間は14cycle減らせるが、4バイト増える。
電大版 Tiny BASIC (bit誌1978年8月号 共立出版)のものも基本的には同じ。NTBの方がサイズが小さい。
昔のプログラムはメモリーを大事にしていたよなあ。今とは大違いである。
MDIV LDAA #16 ;
STAA LPCT ;
CLRA ;
MDV1 ROL 3,X ; 7 2
ROL 2,X ; 7 2
ROLA ; 2 1
ROLB ; 2 1
SUBA 1,X ; 5 2
SBCB 0,X ; 5 2
MDV4 PSHB ; 4 1
EORB 0,X ; 5 2
PULB ; 4 1
SEC ; 2 1
BPL MDV2 ; 4 2 ↑47cycle
ADD ADDA 1,X ; 5 2
ADCB 0,X ; 5 2
CLC ; 2 1 ↑12cycle
MDV2 DEC LPCT ; 7 6
BNE MDV1 ; 4 2 ↑11cycle
MDV3 ROL 3,X ; 7 2
ROL 2,X ; 7 2
RTS ; 5 1
NTBのソースは下記のサイトに掲載されている。
拙作のGAMEクロスコンパイラの除算ルーチン(1)
EtchedPixels氏のFuzix-Compiler-Kitの除算を参考にして、少し高速化したもの。
数の大小によらず16回のループが発生するのだが、小さな数だと無駄なので、先頭で256未満なら下位バイトを上位に移動している。ループ回数も8回に減る。
インデックスアドレッシングを使っていないので、IXはループカウンタとして利用している。ダイレクトページをカウンタとして使うと6サイクル必要だが、IXなら4サイクルで済む。
引き算の結果、引けた時と引けなかった時の処理を分けて、無理に合流させないようにしている。サイズは増えるが処理時間は減る。
*
* DIVIDE Positive number
* W68 = W68/W66 AB=MODULO
* IX is destroyed
*
DIVPOS LDB W68 ; 3 3 the dividend less than or equal to 255 (<=255?)
BNE DIVPOS00 ; 4 2 ↑7cycle overhead
LDA W68+1 ; 3 2 W68 = W68<<8
STAA W68 ; 3 2
STAB W68+1 ; 3 2 clear W68+1
LDX #8 ; 3 3
BRA DIVPOS10 ; 4 2 AccB is 0, so the jump destination is CLRA.
DIVPOS00 LDX #16 ; 3 3
CLRB ; 2 1
DIVPOS10 CLRA ; 2 1 7cycle for preparation
DIVPOS01 ASL W68+1 ; 6 3
ROL W68 ; 6 3
ROLB ; 2 1
ROLA ; 2 1
SUBB W66+1 ; 3 2
SBCA W66 ; 3 2
BCS DIVPOS02 ; 4 2 ↑26cycle
INC W68+1 ; 6 3
DEX ; 4 1
BNE DIVPOS01 ; 4 2 +14cycle => 40cycle/loop => 640cycle for 16bit repetitions
RTS ; 5 1 5cycle
DIVPOS02 ADDB W66+1 ; 3 2
ADCA W66 ; 3 2
DEX ; 4 1
BNE DIVPOS01 ; 4 2 +14cycle => 40cycle/loop => 640cycle for 16bit repetitions
RTS ; 5 1 5cycle
- BASICMASTER/GAME-CC1 at main · zu2/BASICMASTER
- Fuzix-Compiler-Kit/support6800/divide.s at main · EtchedPixels/Fuzix-Compiler-Kit
拙作のGAMEクロスコンパイラの除算ルーチン(2)
現在は引き放し法を使っている。最初はコンピュータアーキテクチャの話(85) 引き過ぎを戻す必要があるのか? | TECH+(テックプラス)を参考に書いたのだが、速度は引き戻し法と大差なかった。
割り算にあるZ80用のルーチンを参考にして書き直したものが、現在のルーチンである。
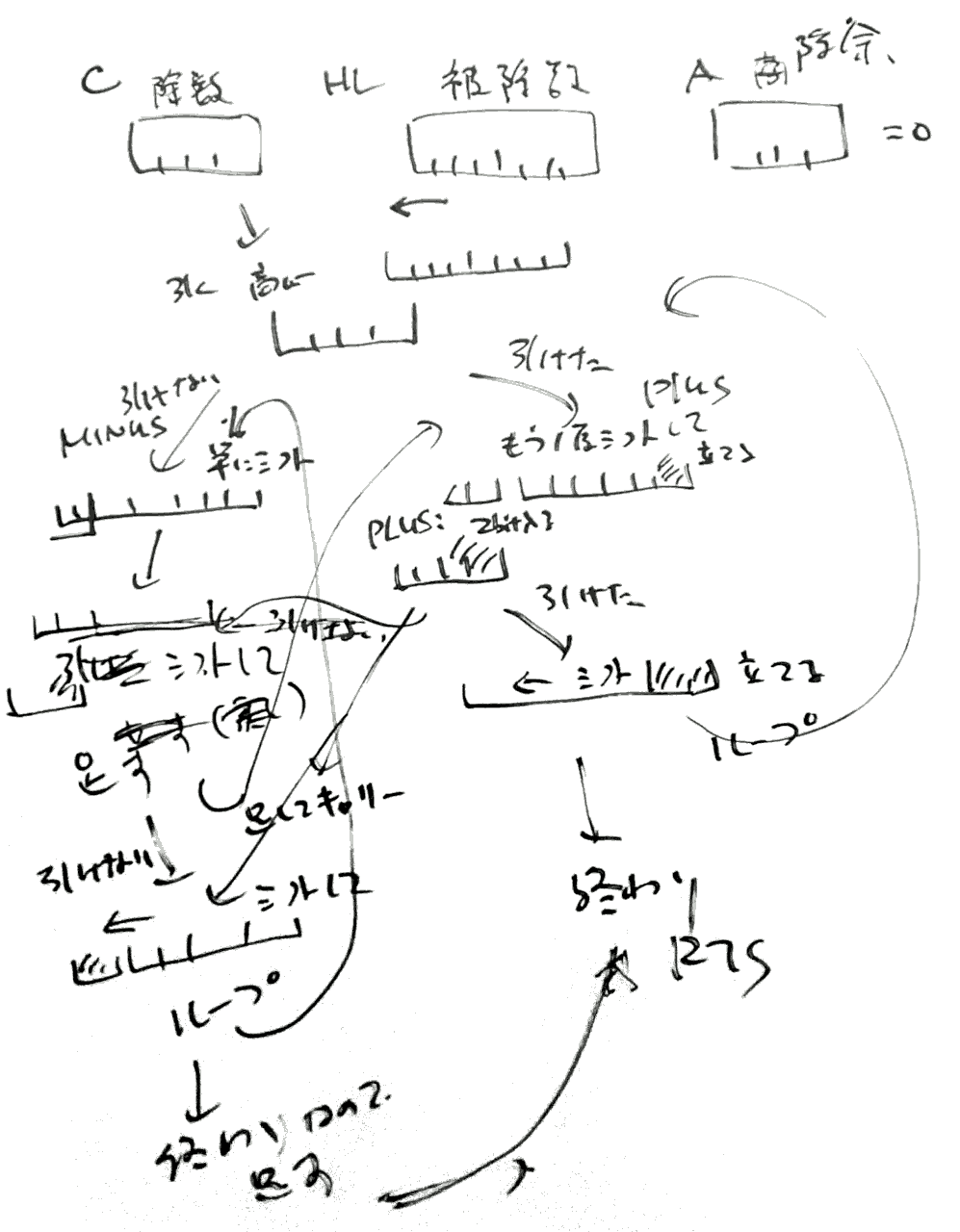
引いて正になるときと負になるときを別のループにしているのがミソ。普通ならフラグを立てて処理するところであるが、それだとフラグの設定・判定に時間がかかる。
これは要するにbit 1980年7月号のプログラミングセミナーにある、プログラム構造とデータの交換である。
算譜の構造が、十分に作られているなら、その構造の上で、いまどこに位置しているかを知ることで相当の情報が得られる。つまり、算譜のトポロジーが十分な情報を含んでいる。一方,構造が貧弱であれば、それだけでは情報不足となるので、それを補うための情報を料として追加してやらなければならない。
bit 1980年07月号 P.31のプログラミングセミナーより引用(注:算譜はプログラム、料はデータ)
フラグ相当の処理をプログラム構造で行なっているので、プログラムサイズは倍近い。その分、ループごとの処理時間は 36,34cycle と最速である。
*
* DIVIDE Positive number / non restoring division algorithm
* W68 = W68/W66 AB=MODULO (W68=Q,W66=M,N=16,A=AccAB)
* cf. https://www.javatpoint.com/non-restoring-division-algorithm-for-unsigned-integer
* cf. https://www.wizforest.com/tech/Z80vs6502/div.html;p2
* IX is destroyed
*
DIVPOS EQU *
LDB W68 ; 3 3 the dividend less than or equal to 255 (<=255?)
BNE DIVPOS00 ; 4 2 ↑7cycle overhead
LDA W68+1 ; 3 2 W68 = W68<<8
STAA W68 ; 3 2
STAB W68+1 ; 3 2 clear W68+1
LDX #8-1 ; 3 3
BRA DIVPOS10 ; 4 2 AccB is 0, so the jump destination is CLRA.
DIVPOS00 LDX #16-1 ; 3 3
CLRB ; 2 1 clear AB
DIVPOS10 CLRA ; 2 1 7cycle for preparation
DIVPOS01 ROL W68+1 ; 6 3
ROL W68 ; 6 3
ROLB ; 2 1 shift AB<<1
ROLA ; 2 1
SUBB W66+1 ; 3 2
SBCA W66 ; 3 2
BCS DIVMNS00 ; 4 2
SEC ; 2 1
ROL W68+1 ; 6 3
ROL W68 ; 6 3 ;
DIVPLS01 ROLB ; 2 1
ROLA ; 2 1
SUBB W66+1 ; 3 2
SBCA W66 ; 3 2
BCS DIVMNS02 ; 4 2 ↑14cycle
DIVPLS02 SEC ; 2 1
DIVPLS03 ROL W68+1 ; 6 3
ROL W68 ; 6 3
DEX ; 4 1
BNE DIVPLS01 ; 4 2 ↑22cycle / 36cycle for plus
RTS ; 5 1
DIVMNS00 ASL W68+1 ; 6 3
ROL W68 ; 6 3 ↑12cycle
DIVMNS01 ROLB ; 2 1
ROLA ; 2 1
ADDB W66+1 ; 3 2
ADCA W66 ; 3 2
BCS DIVPLS03 ; 4 2 ↑14cycle
DIVMNS02 ASL W68+1 ; 6 3
ROL W68 ; 6 3
DEX ; 4 1
BNE DIVMNS01 ; 4 2 ↑20cycle / 34cycle for minus
ADDB W66+1 ; 3 2
ADCA W66 ; 3 2
RTS ; 5 1
追記: 現在のchibicc-6800の16bit除算は28-34cyc/loopであり、復元法なのに上記よりも速い。ループ展開しない場合でも31-37cycである。
他のCPUの例
割り算は、Z80と6502で16bit/8bitの割り算を行うルーチンを比較したもの。
Z80 Routines:Math:Division - WikiTIは Z80の各種除算ルーチンを載せている。
下はZ80 Routines:Math:Divisionに掲載されている Z80用16/16 division。小さい。
限られているとは言え、16bit演算が使えるZ80は羨ましい。
div_ac_de:
ld hl, 0
ld b, 16
_loop:
sll c
rla
adc hl, hl
sbc hl, de
jr nc, $+4
add hl, de
dec c
djnz _loop
ret
リンク
- GAME68コンパイラ : 電子工作やってみたよ
- Nakamozu Tiny Basic /ASCII
- Fuzix-Compiler-Kit/support6800/divide.s at main · EtchedPixels/Fuzix-Compiler-Kit
- BASICMASTER/GAME-CC1 at main · zu2/BASICMASTER
- 6502.org • View topic - UM* (multiplication) bug in common 6502 Forths
- 割り算
- Z80 Routines:Math:Division - WikiTI
- Reverse-engineering the division microcode in the Intel 8086 processor
コメント