
GAME68クロスコンパイラを書いてみた(2) (ベーシックマスター開発 その21) | ず@沖縄の続き。
コンパイラの改良は意外に面白く、最適化の勉強の勉強も兼ねてあれこれ手を入れてみた。最新版は以下に置く。
どれぐらい速くなったのか?
ASCII誌 GAME品定めベンチマーク1-7までの合計で1.50秒。公開初版が5.00秒だったので、3.3倍速。
(このベンチマークのBASIC版はASCII 1978年1月号、オリジナルはKillobaud誌1977年7月号掲載)
| 処理系 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 備考 |
|---|---|---|---|---|---|---|---|---|
| GAME68 | 1.55 | 4.60 | 9.85 | 10.30 | 13.50 | 22.36 | 29.16 | インタプリタ |
| GAME68-CC1 | 0.08 | 0.11 | 1.06 | 0.66 | 0.68 | 1.01 | 1.40 | コンパイラ初期版 |
| GAME68-CC1 | 0.06 | 0.05 | 0.78 | 0.48 | 0.50 | 0.81 | 1.15 | 高速化版(2024/8/10) |
| GAME68-CC1 | 0.05 | 0.05 | 0.08 | 0.13 | 0.16 | 0.40 | 0.63 | 最新版(2024/9/23) |
| GAME80 Compiler | 0.08 | 0.08 | 1.21 | 1.26 | 1.28 | 1.68 | 1.96 | ASCII 1979/7 |
| GAME-MZ Compiler | 0.1 | 0.1 | 1.7 | 1.7 | 1.8 | 2.1 | 2.3 | ASCII 1979/10 |
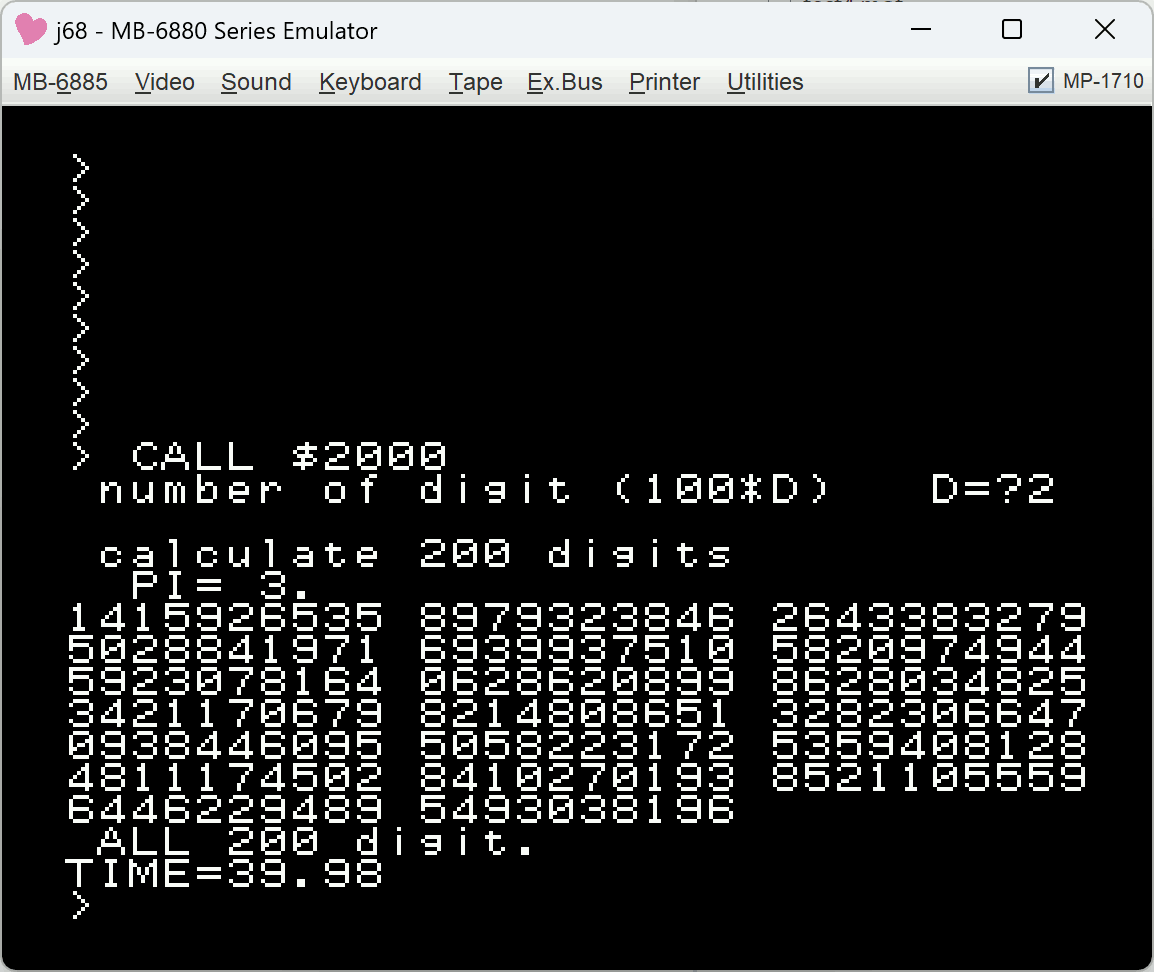
ふるいによる素数表やPIの計算も2-3倍速になっている。
| 処理系 | prime | pi100 | pi200 | 備考 |
|---|---|---|---|---|
| GAME68 | 21.73 | 149.91 | 586.53 | インタプリタ |
| GAME68-CC1 | 2.93 | 28.98 | 111.28 | コンパイラ初期版 |
| GAME68-CC1 | 2.53 | 23.43 | 90.10 | 高速化版 |
| GAME68-CC1 | 1.30 | 10.13 | 39.98 | 2024/09/23版 |
以下、何をしたら速くなったのかを書いておく。
ライブラリを高速化する
MC6800は乗除算命令を持っていないので、サブルーチンを呼び出すのだが、このサブルーチンが遅い。一般に使われているものは素直に作られていてメモリ効率は良いが速度は遅い。
速いアルゴリズムに置き換えて、さらに細かく改良した。また小さな数値の乗除算も多いので、上位バイトが0のときはループ回数を減らすようにした。
乗算は、“Dr Jefyll’s method”、除算は引き放し法を使っている。
2の累乗による乗算を左シフトで置き換えるのはよく知られたテクニックだが、除算も少々手間はかかるが右シフトに置き換えできる。
また、定数による除数のうちよく使われるものは個別に高速化ルーチンを呼ぶようにする(10で割る場合など)。
- Binary Math Tricks: Shifting To Divide By Ten Ain’t Easy | Hackaday
- Jones on reciprocal multiplication
最近のCPUでは、除算を逆数の乗算で置き換える高速化を行うコンパイラも多いが、MC6800の場合はそもそも乗算も遅いのでかえって遅くなりそう。10で割る場合は良く使うので、そこだけ個別ルーチンを起こした。
剰余を求める演算は、元々は除算で得られた余りを使っていたが、除数が定数の場合は高速化できる。
- 剰余を高速に求める | CAmiDion blog
- Is it possible to make x%10 (modulus 10) with bitwise operators in C? – Stack Overflow
- Jones on modulus without division
10進出力や乱数生成なども素直に作ると遅いので、これも速いアルゴリズムに置き換える。
10進出力は、当初は各桁を10000,1000,100,10,1 で割った余りを表示していたが、これでは16bit除算が5回呼ばれるので非常に遅い。素直に各桁を引き算した方がループ回数が減るので引き算に変えた。現在は引き放し法に似た考え方で引き算・足し算を各桁で交互に行うアルゴリズムを使っている。
乱数生成はxorshiftと呼ばれるルーチンに置き換えた。乱数の周期も2^16-1と長い。初期値が0だと0のままになるのが欠点。
スタック演算からメモリ演算に変更
当初は素直にスタックマシンとして実装していたが、実はMC6800のスタック演算は遅い。PSHB/PSHAがそれぞれ4cycle、積まれたデータを消すためのINSも4cycleである。
インデックスアドレシングもダイレクトアドレッシングより2cycle遅いので、ループ内にあるとかなり遅くなる。
CやPascalなど、ローカル変数が必要な言語はインデックス経由でアクセスしないといけないけど、GAMEやBASICなら0ページに置き換えた方が速い。
アドレス計算を使い回す
6800は16bit演算命令がINX/DEXしかない。しかもIXとAccAB間の転送命令もないので、アドレス計算には多大なコストがかかる。なるべくアドレス計算を減らして使いまわせるようにする。
初期のバージョンは配列アクセスのたびにアドレス計算のコードを出していた(GAMEの配列はCのポインタのように使えるので、添字は負になっても良い)。
; (ND_LINENUM 310 '310 W:-$1F)=$F9 W:-$1E)=$FB W:-$1D)=$F9')
.LN310 EQU *
; (ND_ASSIGN (ND_ARRAY1 str=W (ND_NUM -31)) (ND_NUM 249))
LDAB #225
LDAA #255
ADDB _W+1
ADCA _W
PSHB
PSHA
LDAB #249
CLRA
TSX
LDX 0,X
STAB 0,X
INS
INS
; (ND_ASSIGN (ND_ARRAY1 str=W (ND_NUM -30)) (ND_NUM 251))
LDAB #226
LDAA #255
ADDB _W+1
ADCA _W
PSHB
PSHA
LDAB #251
CLRA
TSX
LDX 0,X
STAB 0,X
INS
INS
現在はなるべく計算したアドレスを使いまわすコードを出す。6800のIXレジスタは0-255までの定数オフセットが使えるので、256単位でアドレスを増減させるようにした。
; (ND_LINENUM 310 '310 W:-$1F)=$F9 W:-$1E)=$FB W:-$1D)=$F9')
.LN310 EQU *
; debug dump_loc_table()
; (ND_ASSIGN (ND_ARRAY1 W (ND_NUM -31)) (ND_NUM 249))
CLRB
LDAA #255
ADDB _W+1
ADCA _W
STAB _TMP0+1
STAA _TMP0
LDAB #249
LDX _TMP0
STAB 225,X
; (ND_ASSIGN (ND_ARRAY1 W (ND_NUM -30)) (ND_NUM 251))
LDAB #251
STAB 226,X
; (ND_ASSIGN (ND_ARRAY1 W (ND_NUM -29)) (ND_NUM 249))
LDAB #249
STAB 227,X
for/doループ内で制御変数を使った配列のアドレス計算は事前に済ませるようにした。
120 X(I)=(%(0)*K+X(I))/M
最適化前のは長くなりすぎるので省略。下記の例では、X(I)のアドレスは事前に_F_XI2_1という変数に計算済み。
; (ND_LINENUM 120 '120 X(I)=(%(0)*K+X(I))/M')
; debug dump_loc_table()
; (ND_ASSIGN (ND_ARRAY2 F_XI2_1 (ND_NUM 0)) (/ (+ (* (ND_MOD (ND_NUM 0)) (ND_VAR K)) (ND_ARRAY2 F_XI
2_1 (ND_NUM 0))) (ND_VAR M)))
LDAB _MOD+1
LDAA _MOD
LDX _K
JSR MULTIPLYX
LDX _F_XI2_1
ADDB 1,X
ADCA 0,X
LDX _M
JSR RDIVIDEX
LDX _F_XI2_1
STAB 1,X
STAA 0,X
この他にも雑多な最適化入れてます。詳しくはソースコード参照。
最適化の参考書・リンク
最近の資料・書籍の最適化は高度すぎて付いていけません。静的単一代入(SSA)の説明が多いのですが、SSAの参考になるTinyなプログラムが無いんですよね。
1980年代のコンパイラの書籍がちょうどMC6800に合ってて良い感じです。1990年代になると並列化がメインになってしまう。
(内容が古いのは否めないです。例がFORTRANだったり、使っている技法(ハッシュなど)の説明も多いし)
acwjは6809用のコンパイラですが、レジスタ割り当ての参考になりました。これを見てからEtchedPixels/Fuzix-Compiler-Kitのソースを読むのが良いのかな。
- acwj/64_6809_Target at master · DoctorWkt/acwj
- EtchedPixels/Fuzix-Compiler-Kit: Fuzix C Compiler Project
- コンパイラ作成の技法 (コンピュータ・サイエンス研究書シリーズ ; 10) – 国立国会図書館デジタルコレクション
- コンパイラの技法 (コンピュータシステム・プログラミングシリーズ) – 国立国会図書館デジタルコレクション
資料
- GAME68コンパイラ : 電子工作やってみたよ
- 低レイヤを知りたい人のためのCコンパイラ作成入門
- snakajima/game-compiler: Game 80 compiler, which I’ve created when I was 18 (’79)
- 第33回 「車輪の再発明」の価値 | gihyo.jp
- GAME80コンパイラ解説 (2003/08/05)
- 6809 / 6800とFLEX: 6800用のGAMEインタプリタとコンパイラを6809に移植
- GAME86 Compiler for MS-DOS
- acwj/64_6809_Target at master · DoctorWkt/acwj
コメント