
いまさらベーシックマスターの開発環境を作ってみる(11) 文字コード(1) | ず@沖縄の続き。
BASICMASTERの機種依存文字(以下BM独自文字)を使ったプログラムが存在するので、それを現在の環境でメンテナンスする方法を考えたい。1バイト文字のみ。改行はCR($0D)である。改行以外の$00-$0Fは、制御文字なので通常のプログラムには含まれない。
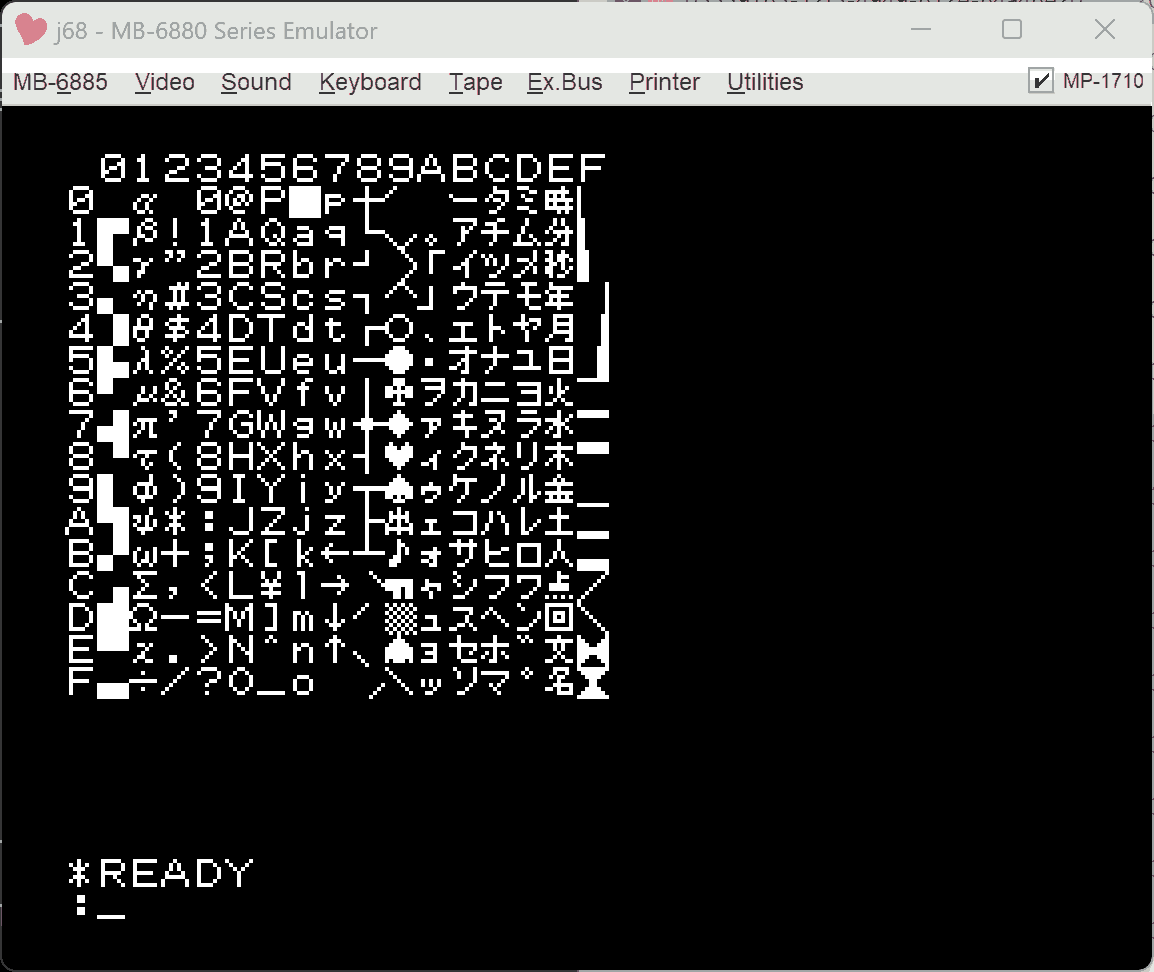
使用例
CHR$に比べると見やすいし、使用バイト数も減る。
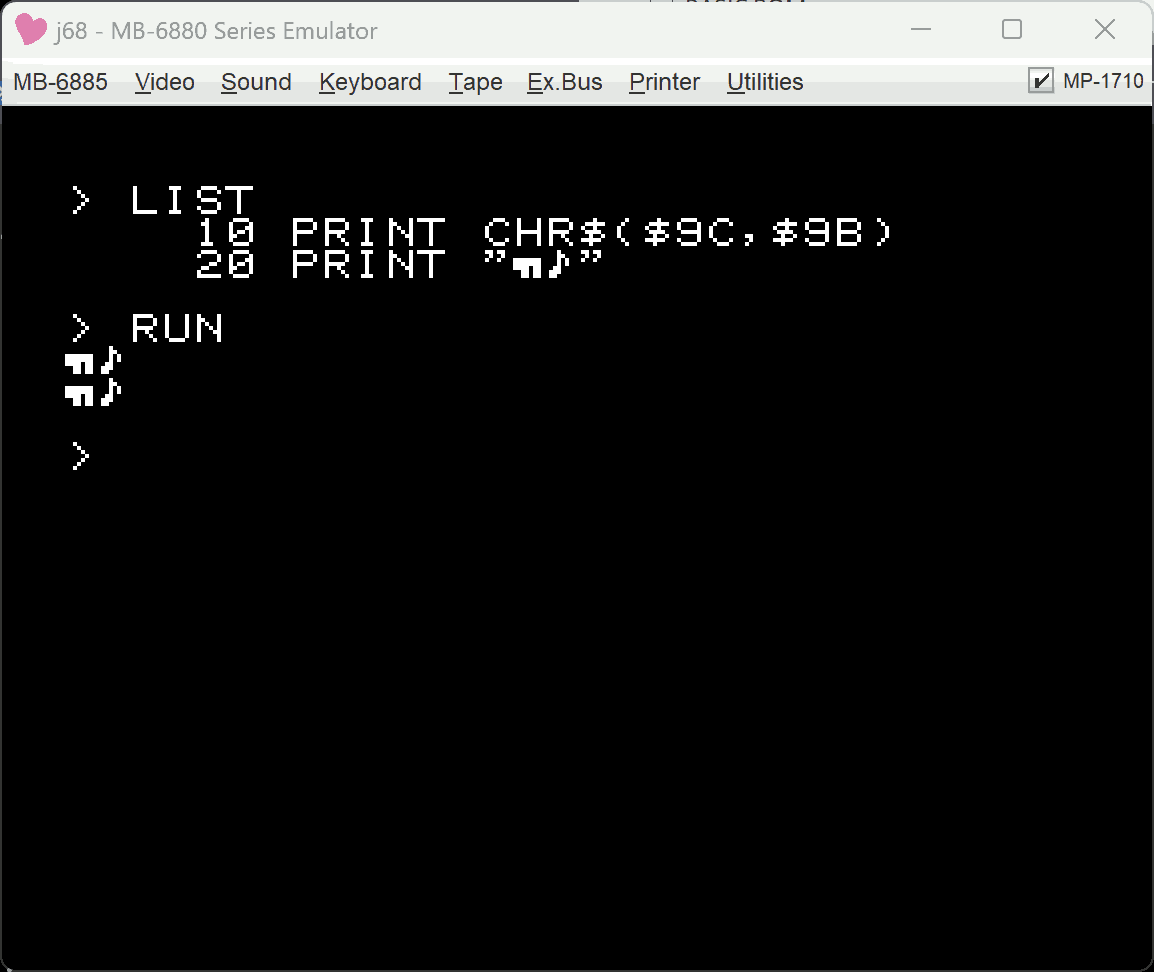
何が問題になるのか
問題はJIS C 6220で未定義だった部分($80-$9F,$E0-$FF)と、制御コード($10-$1F)、本来は”`”や”{“などが入っているはずのコード($60,$7B-$7E)だ。
ここにBM独自文字が入っているので、現代の普通の環境で使うと文字化けするし、そもそも扱えないこともある。
例えば、BM独自文字が含まれたテキストをUTF-8だと思って使ってしまうと、$80-$FFの部分はマルチバイト文字と解釈されて処理がおかしくなってしまう。$10-$1Fは制御文字なので、こちらもおかしくなる。
JIS C 6220(JIS X 0208)の文字だけを含むテキストであれば、CP932(シフトJIS)だと思って処理できればなんとかなる。改行コードがCRだが、これは些細な問題だ。カタカナが見えるだけでもありがたい。
ただし、$80-$9F、$E0-$FFはシフトJISの1バイト目と解釈されるので、ここを含むテキストは処理がおかしくなる。UTF-8と同じく $10-$1Fは制御コードなので扱えない。
2バイト以上の文字を含むコードだからおかしくなるわけで、1バイト文字しかないコード(IBM-PCのCP437など)を使えば処理はできる、けれども、文字は化ける。
では、CP-437のフォントを差し替えて……って考えたが、これは泥沼に続く道なので別の方法を考えることにした。
{kind=link}
続く
コメント